Эпизод 35.
5 метрик мониторинга, которые решают 80% проблем
Оглавление:
Инструменты мониторинга и логирования
Схемы C4 - мониторинг и observability одного микросервиса
Полезные ссылки

Для многих аналитиков и разработчиков нефункциональные требования к системе — тёмный лес. Понятно, что «система должна работать быстро и надёжно», но вот какие именно цифры написать в ТЗ, какие метрики указать и как всё это потом проверять — часто остаётся загадкой.
Мониторинг — один из ключевых инструментов, связанных с архитектурой и инфраструктурой, который позволяет не на словах, а в реальности проверить, выполняются ли нефункциональные требования.
Telegram-канал сообщества: https://t.me/getanalysts
В этом эпизоде мы разложим по полочкам:
- что именно нужно мониторить на проекте,
- какие инструменты обычно настраивают,
- и главное — какие конкретные метрики и показатели можно и нужно писать в ТЗ.
После выпуска у вас будет структурированное понимание, какие цифры писать в НФТ и как измерять качество системы, а не просто «надеяться, что всё ок».
Тайм-коды эпизода:
01:30 | Мониторинг и диагностика IT-систем: что это такое и зачем нужен системный мониторинг.
06:25 | Что нужно мониторить в продакшене: ключевые метрики и показатели мониторинга для вашей системы.
10:00 | Логирование и трассировка запросов: что это, зачем нужны, как работают и как связаны с системным мониторингом.
11:45 | Конкретные нефункциональные требования к мониторингу: какие цифры по времени отклика писать в спецификации системы.
14:06 | Как мониторить мобильные приложения.
16:21 | Нефункциональные требования к нагрузке: какие значения % CPU и ресурсов указывать в требованиях.
20:10 | Инструменты мониторинга и observability: что выбрать, когда и зачем. Стандарт OpenTelemetry и пример схемы архитектуры.
27:35 | Реальные кейсы, где мониторинг помогает проектам. Мониторинг кэширования.
33:04 | Кто на проекте настраивает мониторинг системы и что для этого нужно.
35:41 | Источники требований к мониторингу: от кого они приходят, в каком виде и как собирать требования к метрикам.
37:53 | Кто и как следит за показателями мониторинга на проекте: процессы, роли и работа с инцидентами.
44:37 | Дашборды мониторинга: как понять, что нужен новый дашборд.
46:27 | Итоги эпизода: рекомендации командам по внедрению мониторинга на разных стадиях проекта и практика «учебных тревог» в IT-проектах.
Екатерина Ананьева,
Основатель сообщества
Системных Аналитиков GetAnalyst
Гости:
Никита Улько,
Техлид VK Tech,
Telegram-канал: @ulkosaurus_hex
Инструменты мониторинга и логирования
OpenTelemetry — стандарт телеметрии (метрики, логи, трейсы)
Набор спецификаций, SDK и агентов для сбора метрик, логов и трейсов из приложений и инфраструктуры и отправки их в разные системы мониторинга/логирования. Это не хранилище, а единый стандарт и слой инструментирования.
Prometheus — мониторинг метрик
Оpen source система мониторинга и алертинга по метрикам. Сохраняет временные ряды метрик в своей БД, опрашивает таргеты по pull-модели и используется как основа для дашбордов (обычно вместе с Grafana).
Elasticsearch + Kibana — логирование + наблюдаемость
Elasticsearch — поисковая и аналитическая система, часто используется как хранилище логов и трейсов.
Kibana — веб-интерфейс для визуализации данных из Elasticsearch: дашборды логов, метрик, APM и других данных наблюдаемости.
Jaeger — распределённый трейсинг
Платформа распределённого трейсинга: собирает и визуализирует трейсы запросов между микросервисами, помогает находить узкие места, задержки и проблемы в цепочке вызовов.
VictoriaMetrics — метрики и мониторинг
Быстрая и масштабируемая time-series база и решение для мониторинга. Часто используется как альтернатива/долгосрочное хранилище для Prometheus, а также как часть собственного observability-стека (метрики + логи).
Zipkin — распределённый трейсинг
Оpen source система распределённого трейсинга. Собирает тайминги вызовов между сервисами, помогает разбирать задержки, ошибки и общую «дорожку» запроса через микросервисы.
Kong (с поддержкой OpenTelemetry) — API Gateway + телеметрия
API Gateway, который «из коробки» поддерживает телеметрию: через OpenTelemetry-плагин Kong умеет отправлять трейсы и метрики в любой OTLP-совместимый backend. Поддержка включается на уровне конфигурации, без переписывания бизнес-кода.
Схемы C4 - мониторинг и observability одного микросервиса
Минимальный набор инструментов мониторинга и логирования для микросервиса
Это инфраструктурная C4-диаграмма, которая показывает, как организовать мониторинг и observability одного микросервиса по стандарту OpenTelemetry с минимальным набором инструментов.
Суть схемы
Универсальный микросервис в системе промаркирован с помощью SDK OpenTelemetry и отправляет метрики и трейсы по OTLP в единый OpenTelemetry Collector.
Коллектор выступает «шлюзом наблюдаемости»: принимает данные, преобразует их и маршрутизирует в разные хранилища и сервисы мониторинга.
Далее данные расходятся по нескольким направлениям:
Prometheus — база временных рядов для метрик.
Метрики, пришедшие в Collector, сохраняются в Prometheus и затем визуализируются в Grafana на дашбордах мониторинга.Zipkin / Jaeger — системы распределённых трейсов.
Collector отправляет туда трейсы запросов, что позволяет анализировать цепочки вызовов между сервисами и время отклика на каждом шаге.Observability ElasticSearch + APM Server — хранилище логов, трейсов и метрик производительности.
APM Server принимает данные производительности от приложений и передаёт их в ElasticSearch, а Kibana используется для построения дашбордов по логам, трейсам и APM-метрикам.
Фиолетовым цветом на схеме выделены опционально подключаемые или альтернативные сервисы.
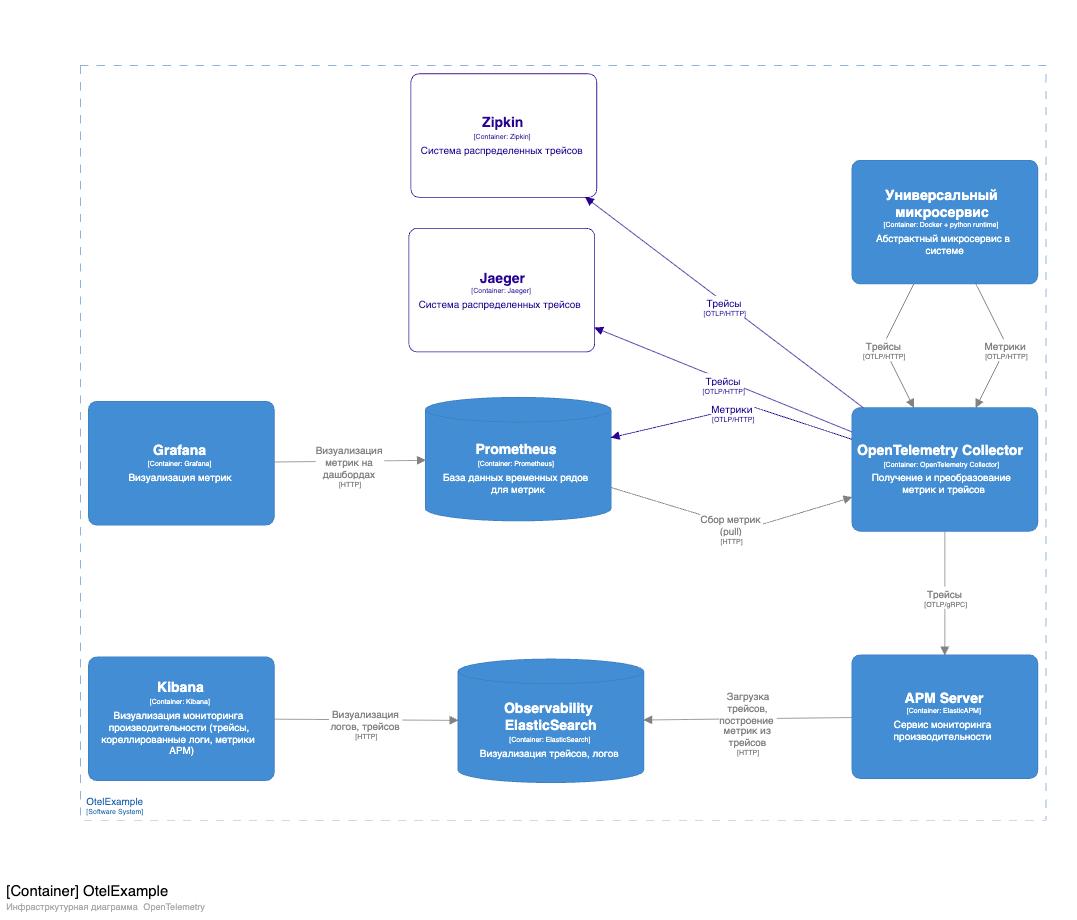
Диаграмма демонстрирует минимальный, но практичный стек наблюдаемости для микросервисной системы.
Расширенный набор инструментов мониторинга и логирования для микросервиса
Это инфраструктурная C4-диаграмма расширенного варианта мониторинга и observability для нескольких сервисов по стандарту OpenTelemetry.
Универсальный микросервис и API Gateway Kong промаркированы через OpenTelemetry SDK и отправляют трейсы, метрики и логи (OTLP/HTTP) в единый OpenTelemetry Collector.
Коллектор выступает шлюзом наблюдаемости: получает данные, нормализует их и маршрутизирует в разные системы хранения и анализа.
В схеме показано, как один Collector может одновременно работать с несколькими backend-ами:
- Prometheus и VictoriaMetrics — базы временных рядов для метрик, которые далее визуализируются в Grafana;
- Jaeger и Zipkin — системы распределённых трейсингов для анализа цепочек вызовов между сервисами;
- Loki и Observability ElasticSearch — хранилища логов и трейсов;
- APM Server + Kibana — мониторинг производительности (APM-метрики, трассировки, корреляция с логами) и построение дашбордов.
Фиолетовым цветом на схеме выделены опционально подключаемые или альтернативные сервисы.

Диаграмма демонстрирует, как вокруг OpenTelemetry Collector можно построить единый контур наблюдаемости для системы с микросервисной архитектурой.
Полезные ссылки
- Репозиторий с примером настройки телеметрии
Пример инструментации FastAPI-приложения с подключенными трейсингом, метриками и сквозными логами. Вся инфраструктура настроена.
https://github.com/ulkenauer/otel_example - Что такое API Gateway и 10 его главных функций
Статья по API Gateway
Ещё эпизоды, которые могут вас заинтересовать



Бесплатное обучение
Получайте полезные материалы и учитесь новому каждый день в наших социальных сетях.






*Instagram и LinkedIn — запрещенные на территории РФ организации

Контакты
+7 (499) 686-15-46
Лицензия №Л035-01255-50/01366872 от 28.08.2024
Практический опыт здесь, 2021-2026
Индивидуальный предприниматель
Алтунин Дмитрий Михайлович
ИНН 503610364488
Мы используем файлы cookie, для персонализации сервисов и повышения удобства пользования сайтом. Если вы не согласны на их использование, поменяйте настройки браузера.